As this WordPress blog doesn’t want to embed interactive visualisations, I’ll publish the full story at Blogspot. This is actually the final challenge of the Data Expedition at School of Data, in which I was lucky to participate. I had to present the results of my data experiments as a data-driven story.
Any instructive feedback, recommendations and criticisms are welcome, because it’s really hard to assess this stuff from my beginner’s position. Also, if you notice any mistakes, which, I’m sure, are numerous, please let me know.
So, below is actually the story. And here’s the full dataset behind the story.
There was an article by Simon Rogers and Lisa Evans on Guardian Datablog, which showed that if we compare the pure CO2 emissions data and the data on CO2 per capita emissions, we can see strikingly different results. The starting point of this analysis was that the “world where established economies have large – but declining – carbon emissions. While the new economic giants are growing rapidly” [in terms of CO2 emissions volume again]. But if we look at the CO2 per capita data, we can see that those rapidly growing economic giants have very modest results, compared to the USA, as well as some really small economies like Qatar or Bahrain.
I decided to have closer look at the data on pure CO2 emissions, CO2 emissions per capita, as well as GDP, in order to see if there are any patterns. Namely, if there is any relationship between GDP growth and CO2/CO2 per capita emissions volume. The general picture can be seen on the interactive visualisation at Blogspot or here. (Honestly, I don’t know why this Google chart prefers to speak Russian when published. Actually, the Russian phrase in the chart’s navigation means ‘same size’.) It is based on the data for the top-10 CO2 emitters combined with top-10 CO2 per capita emitters (only those though, for which WB data on GDP had some information) and actually the GDP data for the period from 2005 to 2009, which was the optimal range in terms of data availability. Plus South Africa for the reasons described below.
Now, is there any relationship between GDP growth (or decline) and the amount of CO2 emissions? Here are some observations.
During the period of 2005 – 2008, all of the presented economies were growing, after which there was a massive decline in the economic growth, quite predictably, because the global economic crisis began in 2008. And we can see a corresponding massive decline of the amounts of CO2 emissions. Generally speaking, by 2008, about 30% of the total of the 21 countries had CO2 emissions growth rate below 100%. After 2008, it was about 60% of the total that had CO2 emissions growth rate below 100%.
Can we really insist that it was only the global economic decline that provoked this decline in CO2 emissions, and not, for example, the results of some green policies? Well, our data doesn’t provide enough information to draw this conclusion. But there is a peculiar thing to mention though.
After 2008, there were actually some economies (again, of our sample list) that continued to grow, namely, China, India, Japan, Singapore, and South Africa. The corresponding CO2 emissions indicators, in terms of growth or declination, are rather different, as can be seen below.
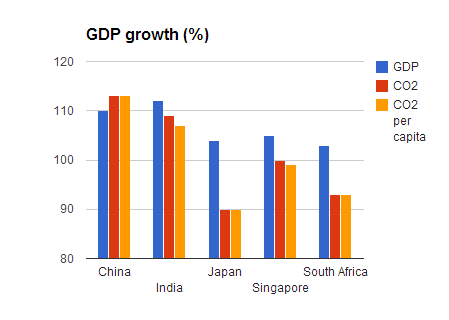
And also, there are five economies that had a considerable GDP decline, but nonetheless a stable CO2 emissions growth.
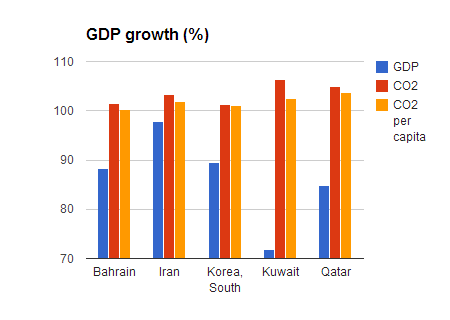
Now, if we look at these ten countries together, we shall see that only in three cases (Japan, Singapore and South Africa) GDP growth is accompanied by CO2 emissions decline. While in the other cases, CO2 emissions keep increasing without any obvious connection to the GDP trends.
***
Last thing I would want to mention is a very general observation. Just for the sake of it, I compared my initial CO2 emissions dataset from U.S. Energy Information Administration (EIA) with another one (Carbon Dioxide Information Analysis Center (CDIAC)).
Here are the total values of the two datasets:

And here’s the total world GDP, according to the data from the World Bank and IMF. These look much more similar (as well as up-to-date):

This basically goes in accord with the observation that governments are paying less attention to the information on CO2 concentration in the atmosphere.
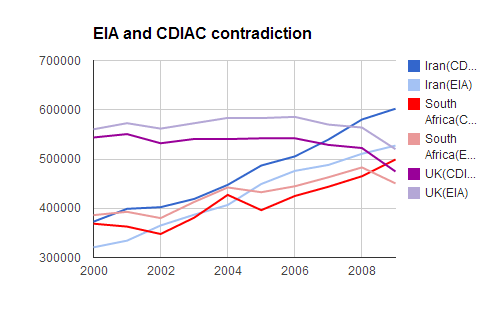
Another observation is that although the total trends in the two CO2 datasets seem to be non-contradictory (even though different) in general, it doesn’t mean that there are no contradictions in some particular cases. For instance, if we look at the top-10 CO2 emitters in both EIA and CDIAC datasets as of 2009, we can see that in CDIAC dataset South Africa takes the tenth position, while in the EIA dataset South Africa is in the twelfth position. Which when visualised shows contradictory trends: according to CDIAC, the volume of CO2 emissions from South Africa increases, and according to EIA, it goes down.